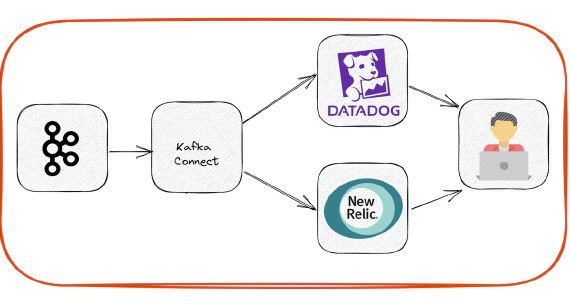
How To Stream Data From Kafka To APM Platforms
In this article, we will see how to stream data from Kafka to apm platforms like DataDog and New Relic. Code used in …
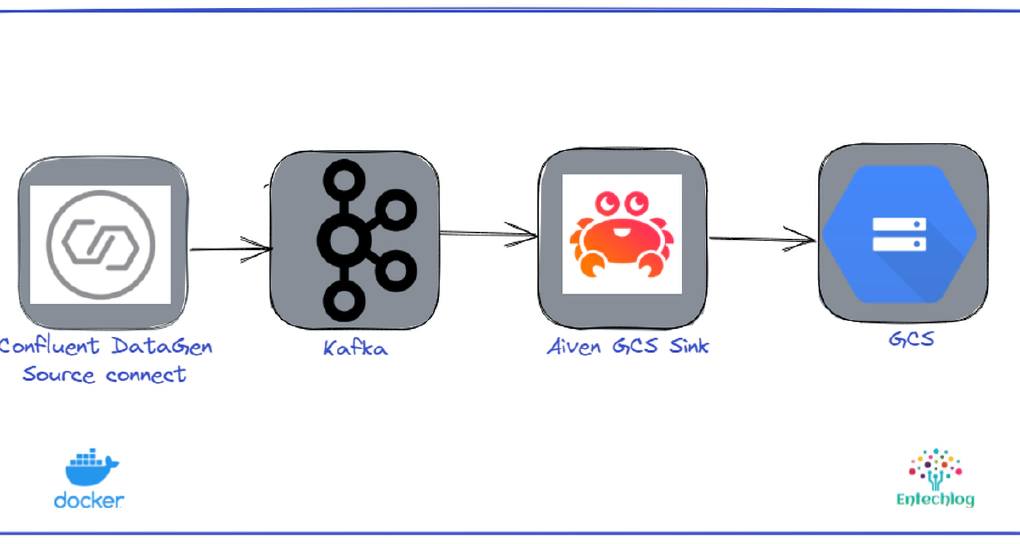

In this article, we will see how to use Aiven’s GCS Sink Connector for Apache Kafka to stream data from Kafka to Google Cloud Storage(GCS). Code used in this article can be found here. We will use Confluent Kafka running in docker and Kafka connect DataGen to generate a stream of data required for the demo.
Login into Google Cloud Account and search for cloud storage in Google Cloud Console
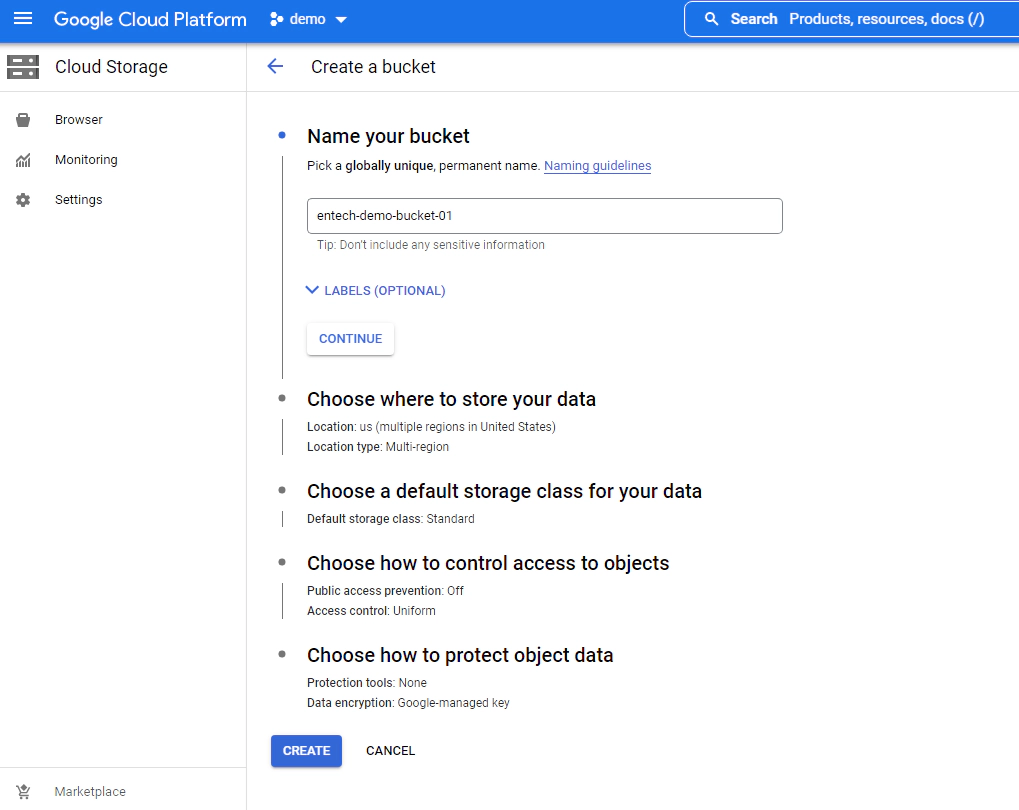
Create bucket with default configuration. The bucket name must be globally unique.
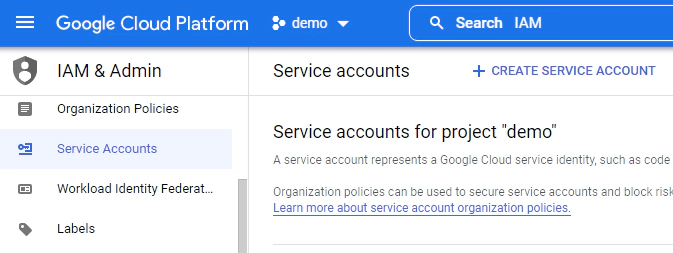
Search for IAM in Google Cloud Console, click service account to create a new service account which will be used by Kafka connect
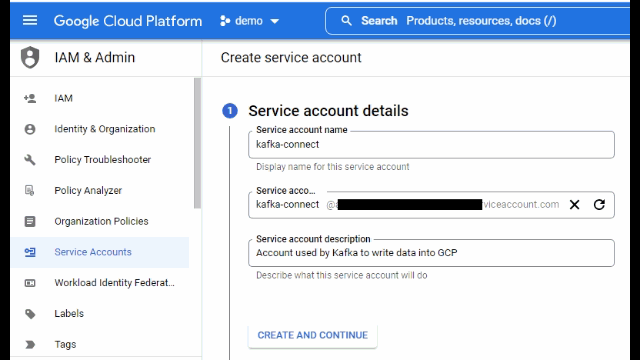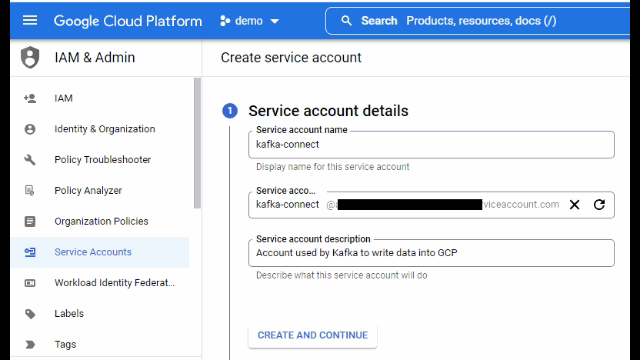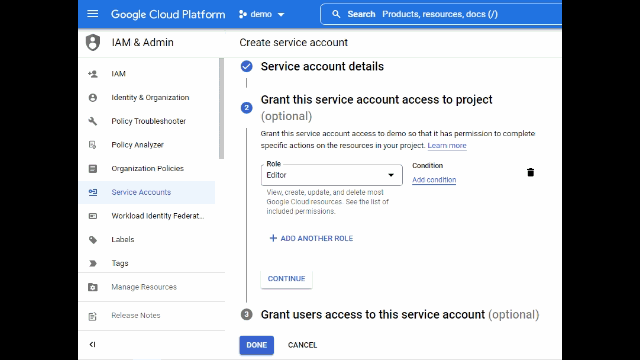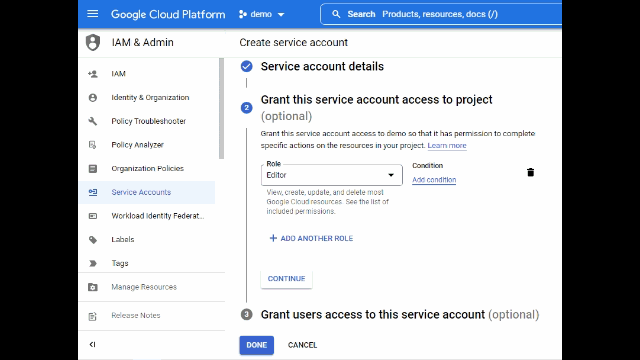
Create service account, grant editor role and select done
After creating the service account, click action –> select manage keys –> add key to create a new key of type json. This will also download a json file which will be used in the Kafka connect

For the purpose of the demo we will be running Kafka and Kafka connect in a docker container
Open a new terminal and cd into kafka-to-gcs directory. This directory contains infra components for this demo
cd kafka-to-gcs
Create a copy of .env.template as .env. This contains all environment variables for docker, but we don’t have any variables which should be changed for the purpose of this demo
Rename the downloaded gcp key to connect-secrets.properties and copy into kafka-to-gcs/kafka-connect/secrets/. This contains the credentials to write to the GCS bucket.
Review the Data generator Kafka source connector config in kafka-connect/config/source/connector_src_users.config. The below configuration will generate sample user data and will write to a topic named user. See here if you wish to customize any of the configuration.
{
"name": "src-datagen-users",
"config": {
"connector.class": "io.confluent.kafka.connect.datagen.DatagenConnector",
"kafka.topic": "users",
"quickstart": "users",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"max.interval": 1000,
"iterations": 10000000,
"tasks.max": "1"
}
}
Review the GCP sink connector config in kafka-connect/config/sink/connector_sink_users.config. The below configuration will generate read data from user topic and will write them to gcp bucket in gzip format. See here if you wish to customize any of the configuration.
{
"name": "sink-gcs-users",
"config": {
"connector.class": "io.aiven.kafka.connect.gcs.GcsSinkConnector",
"tasks.max": "1",
"topics": "users",
"gcs.bucket.name": "entech-demo-bucket-01",
"gcs.credentials.path": "/opt/confluent/secrets/connect-secrets.json",
"format.output.type": "jsonl",
"format.output.envelope": false,
"format.output.fields": "value",
"_format.output.fields": "key,value,offset,timestamp,headers",
"file.name.prefix": "raw/",
"file.compression.type": "gzip",
"file.name.timestamp.timezone": "UTC",
"file.name.timestamp.source": "wallclock",
"file.name.template": "y={{timestamp:unit=yyyy}}/m={{timestamp:unit=MM}}/d={{timestamp:unit=dd}}/H={{timestamp:unit=HH}}/{{topic}}-{{partition:padding=true}}-{{start_offset:padding=true}}.gz",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"_key.converter": "org.apache.kafka.connect.converters.ByteArrayConverter",
"key.converter.schemas.enable": false,
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"_value.converter": "org.apache.kafka.connect.converters.ByteArrayConverter",
"__value.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter.schemas.enable": false,
"errors.tolerance": "all",
"errors.deadletterqueue.topic.name": "connect.sink.dlt.gcs.users",
"errors.log.include.messages": true,
"errors.deadletterqueue.context.headers.enable": true,
"errors.deadletterqueue.topic.replication.factor": 1
}
}
Start Kafka container by running
docker-compose up -d --build
Validate the containers by running
docker ps
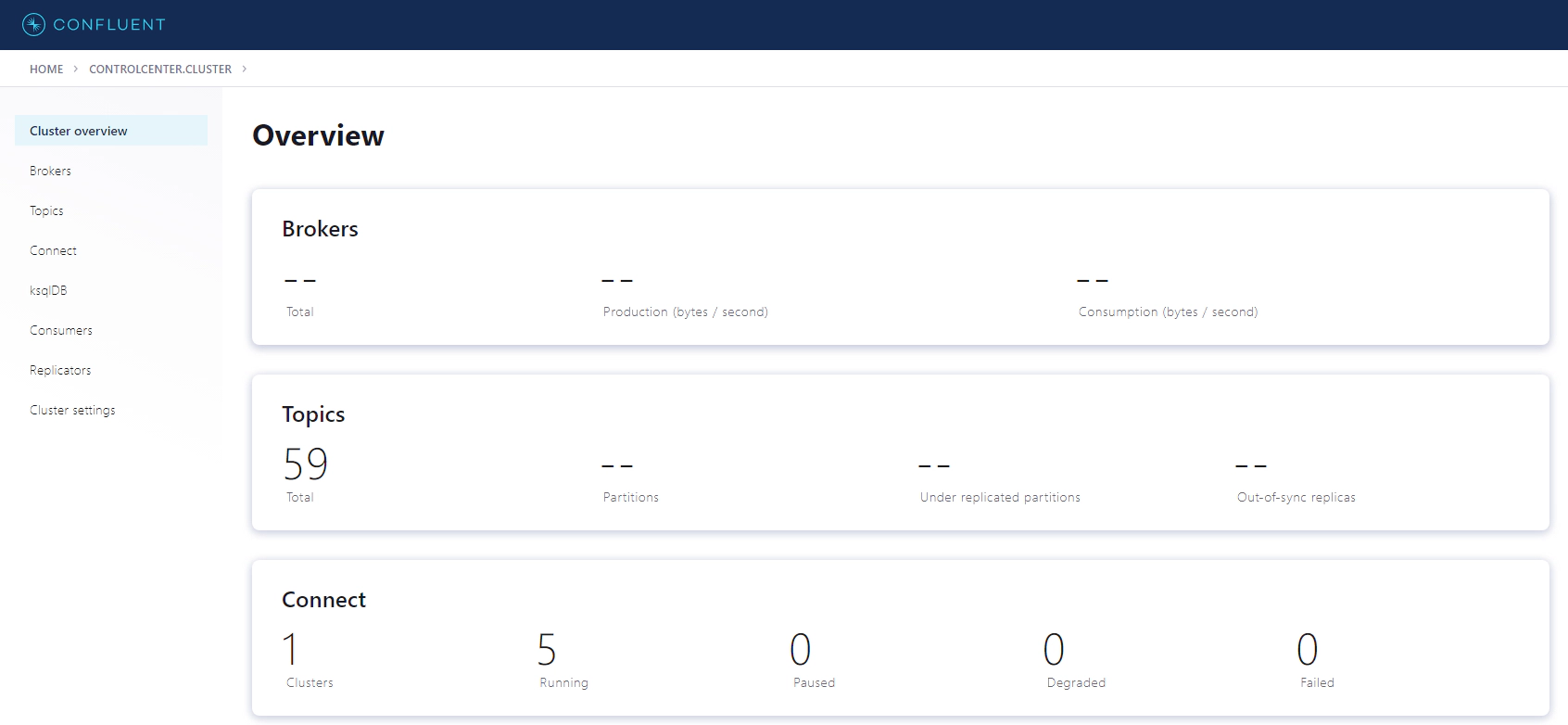
Validate the health of cluster and connectors by navigating to Confluent control center UI. Control center is not required for the purpose of this demo, but it’s good to have a dashboard which shows the health of the services
Validate the data in GCS by navigating to the gcs bucket
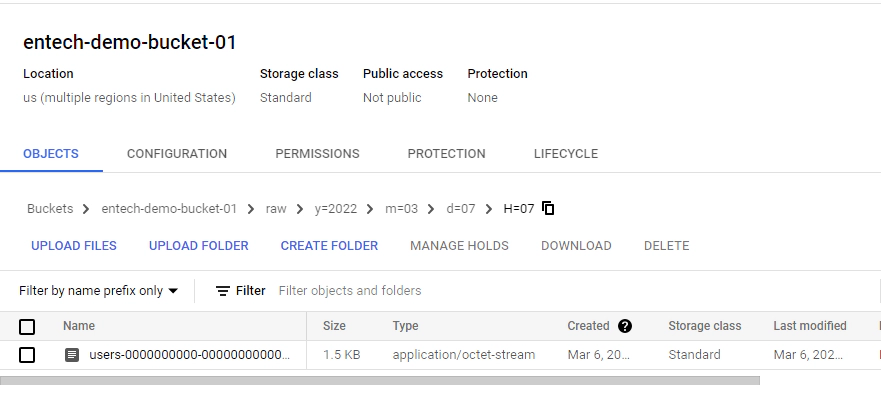
You should see the data in Kafka topics written to the bucket with a file name format specified in the sink connector configuration
Open a new terminal and cd into kafka-to-gcs directory. Run the below command to delete the docker containers and related volumes
docker-compose down -v --remove-orphans
Hope this was helpful. Did I miss something ? Let me know in the comments.
In this article, we will see how to stream data from Kafka to apm platforms like DataDog and New Relic. Code used in …
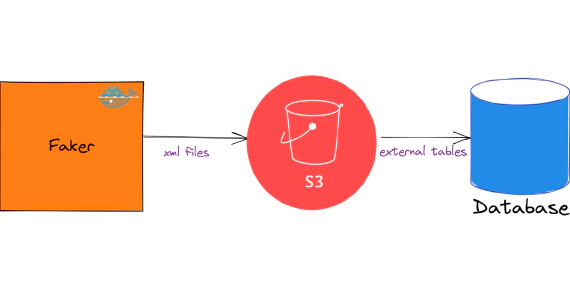
In this article, we will see how to load and use XML files in snowflake. Code used in this article can be found here. …