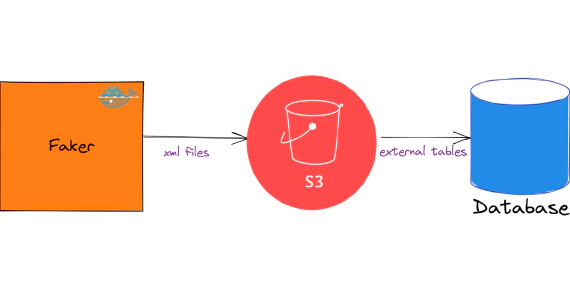
Exploring XML In Snowflake
In this article, we will see how to load and use XML files in snowflake. Code used in this article can be found here. …
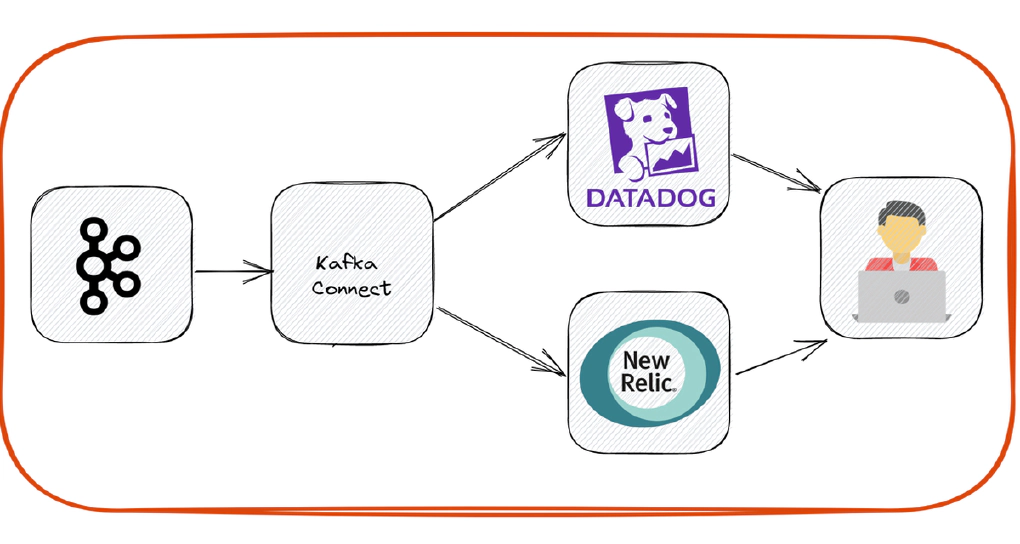

In this article, we will see how to stream data from Kafka to apm platforms like DataDog and New Relic. Code used in this article can be found here. Download the folder to get started. To have stream of data, we will run kafka-avro-console-producer and kafka-console-producer in loop.
To ingest data into Datadog and New Relic you need API keys. API keys are used to authenticate and verify your identity. API keys are unique to your organization.
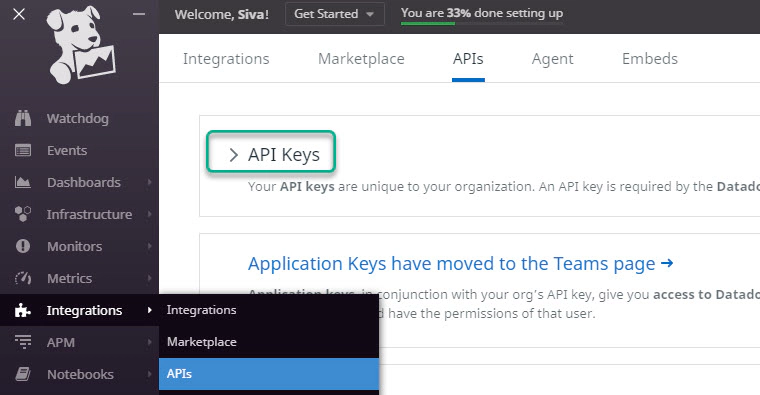
Create API key for DataDog by navigating to Integration > APIs > API Keys in your DataDog account portal.
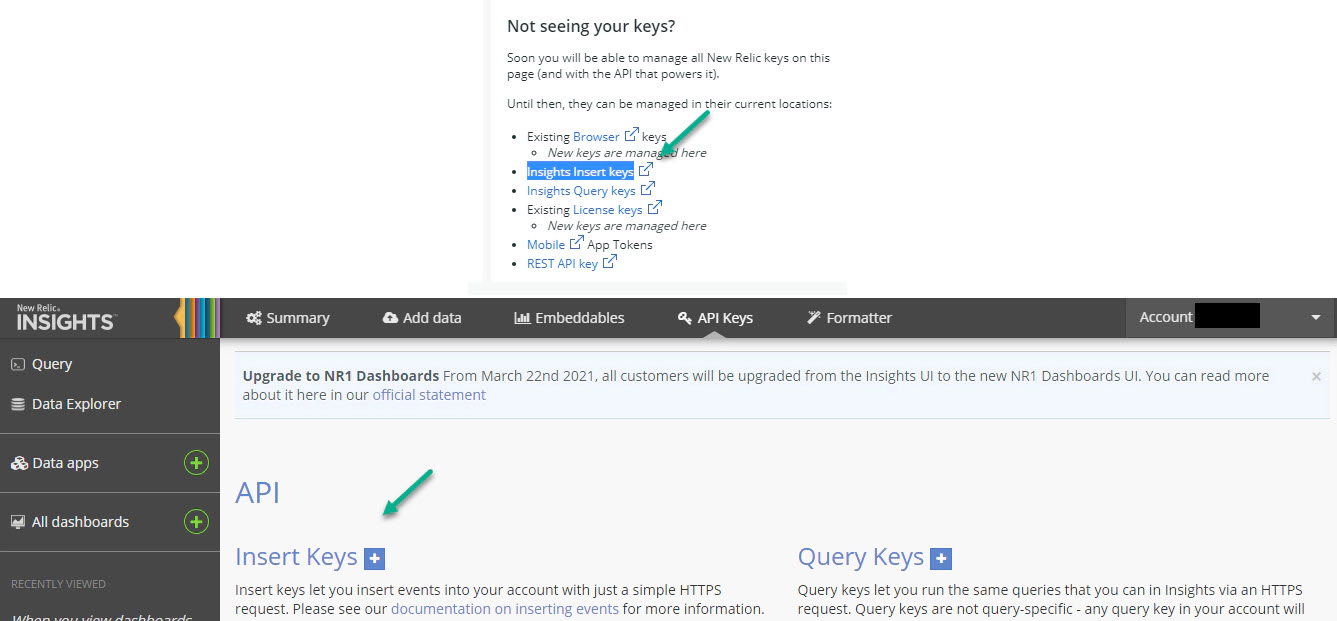
Create API key for New Relic by navigating to API Keys in your New Relic account portal.

New Relic has different type of keys, the one we need to ingest metrics is Insights Insert keys
The docker-compose.yml will bring up following services
⏩ Kafka (Zookeeper, Broker, Kafka Connect, Schema Registry, Control Center)
⏩ Kafka Client (Generates mock data and writes to Kafka topic using kafka-avro-console-producer and kafka-console-producer )
Here is the list of steps which should be done before bringing up the docker services
✅ Create a copy of /kafka-connect/secrets/connect-secrets.properties.template as /kafka-connect/secrets/connect-secrets.properties and update with DataDog and New Relic API keys.
✅ Create a copy of .env.template as .env.
Now we have all required artifacts and the next step to start the Kafka services. Here we will bring up kafka, produce some data by calling kafka-avro-console-producer and kafka-console-producer in a loop and write the events from Kafka topic to apm platforms. All these will happen automatically when we bring up docker-compose.yml
Here is the configuration for DataDog connector
{
"connector.class": "io.confluent.connect.datadog.metrics.DatadogMetricsSinkConnector",
"tasks.max": 1,
"confluent.topic.bootstrap.servers": "broker:9092",
"topics": "backend-server-capacity",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": false,
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schemas.enable": true,
"value.converter.schema.registry.url": "http://schema-registry:8081",
"datadog.api.key": "${file:/opt/confluent/secrets/connect-secrets.properties:datadog-api-key}",
"datadog.domain": "COM",
"behavior.on.error": "fail",
"reporter.bootstrap.servers": "broker:9092",
"reporter.error.topic.name": "datadog-sample-events-error",
"reporter.error.topic.replication.factor": 1,
"reporter.result.topic.name": "datadog-sample-events-success",
"reporter.result.topic.replication.factor": 1
}
DataDog connector expects
✅ Kafka records in specific JSON/AVRO format required by DataDog API
✅ Schema for the record in schema registry
Here is the configuration for New Relic connector
{
"connector.class": "com.newrelic.telemetry.metrics.TelemetryMetricsSinkConnector",
"tasks.max": 1,
"confluent.topic.bootstrap.servers": "broker:9092",
"topics": "newrelic-sample-events-no-schema",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": false,
"value.converter": "com.newrelic.telemetry.metrics.MetricsConverter",
"value.converter.schemas.enable": false,
"api.key": "${file:/opt/confluent/secrets/connect-secrets.properties:newrelic-api-key}",
"behavior.on.error": "fail"
}
New Relic connector expects
✅ Kafka records in specific JSON format required by New Relic API. Read more about the supported JSON format here
✅ Schema is not required
✅ Advisable to make sure timestamp in the event is correct and current.
Start the application by running docker-compose up --remove-orphans -d --build in the directory with docker-compose.yml
Validate the status of docker containers by running docker-compose ps
Validate Kafka topics and connector by navigating to Control Center at http://your-machine-name:9021/clusters/.
Metrics and choosing the metric name, which is backend.server_capacity in this example.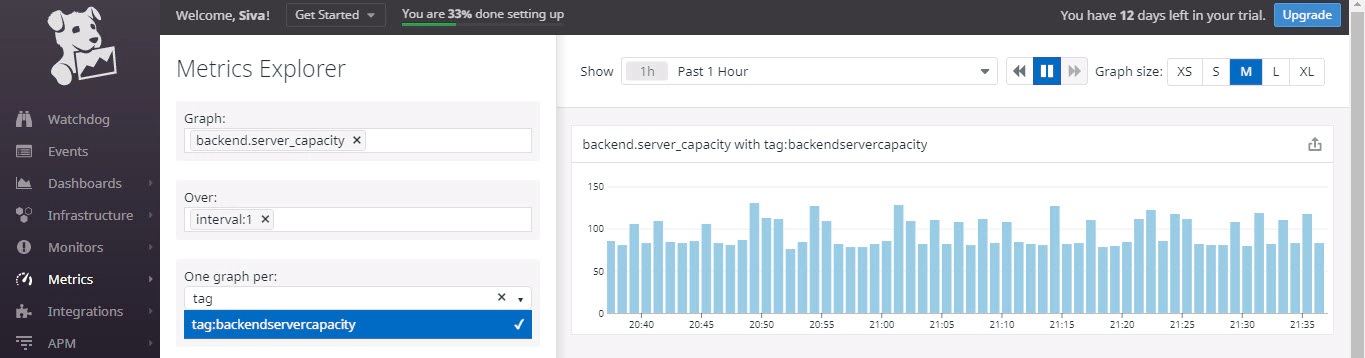
Notebooks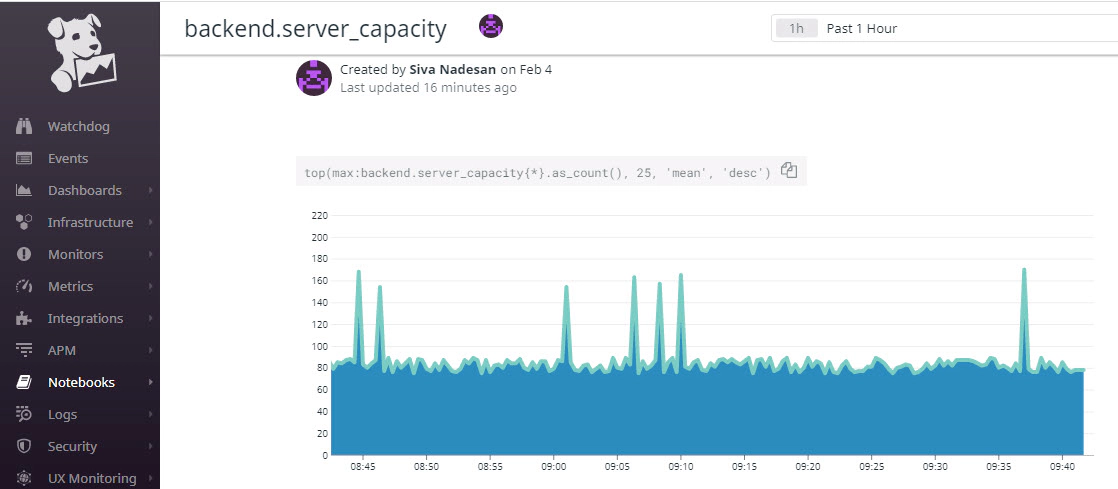
Validate data in New Relic by navigating to Data Explorer

Create the NRQL(New Relic’s SQL-like query language) as per your needs, here is an example query
SELECT average(`cache.misses`)
FROM Metric FACET host.name SINCE 30 MINUTES AGO TIMESERIES;
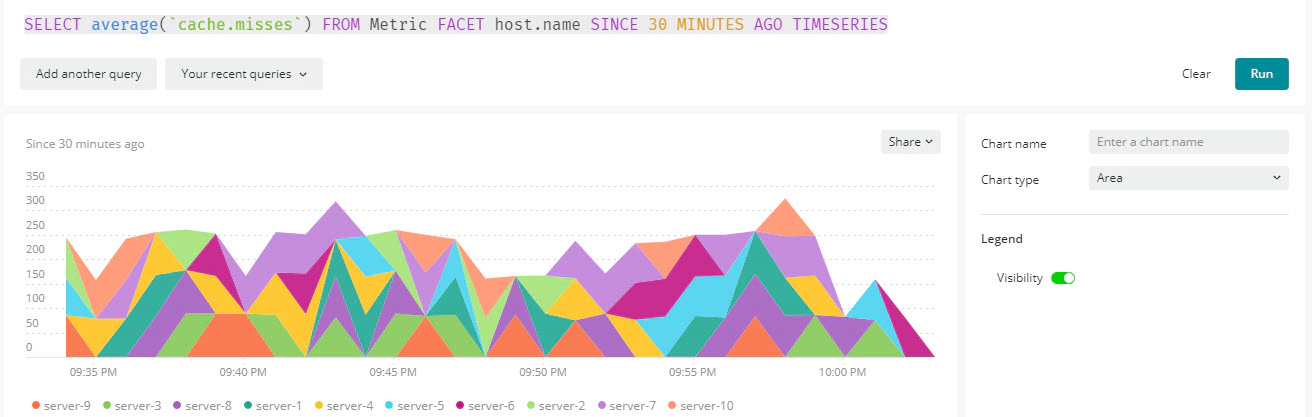
Hope this was helpful. Did I miss something ? Let me know in the comments and I’ll add it in !
docker container ls -adocker-compose downdocker-compose down --volumesdocker rm $(docker ps -q -f status=exited)
In this article, we will see how to load and use XML files in snowflake. Code used in this article can be found here. …
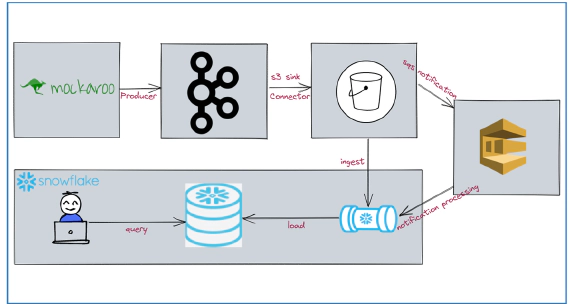
In this article, we will see how to stream data from kafka to snowflake using S3 and Snowpipe. Code used in this article …