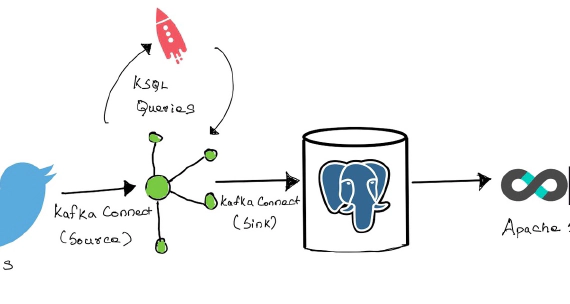
Exploring ksqlDB, Superset with real time Twitter data feed of my favorite celebrities
Prerequisites Install Confluent platform for your operating system using …
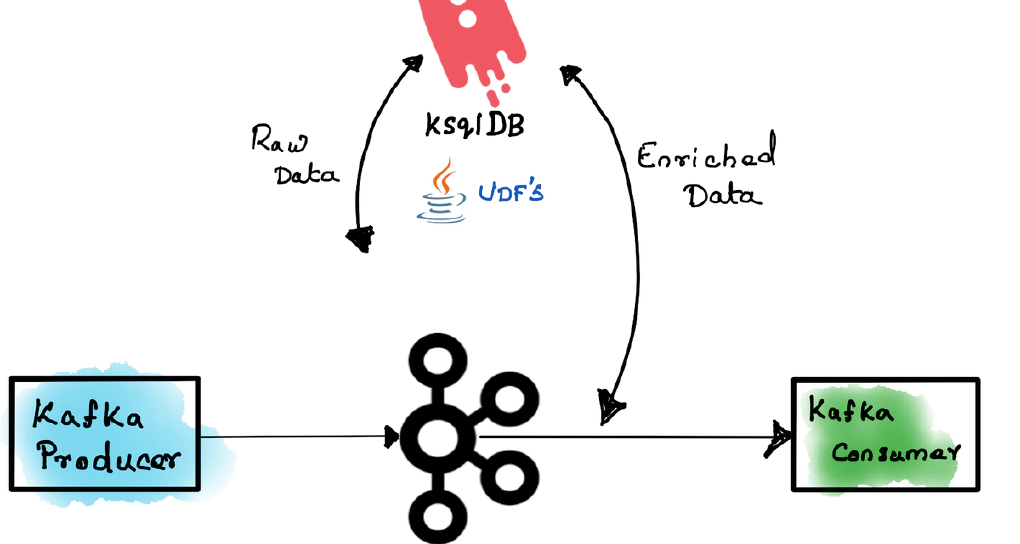

In this article, we will go over the process to create and validate ksqlDB UDFs.
sudo apt install mavenOnce we have the prerequisites, Lets go ahead and add the maven repositories from Confluent to your ~/.m2/settings.xml file
<settings>
<profiles>
<profile>
<id>myprofile</id>
<repositories>
<!-- Confluent releases -->
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
<!-- further repository entries here -->
</repositories>
</profile>
</profiles>
<activeProfiles>
<activeProfile>myprofile</activeProfile>
</activeProfiles>
</settings>
Run the following command and fill in required details. Make sure to use the right profile if you have multiple maven profiles by using -Pmyprofile parameter
mvn -Pmyprofile archetype:generate -X \
-DarchetypeGroupId=io.confluent.ksql \
-DarchetypeArtifactId=ksql-udf-quickstart \
-DarchetypeVersion=5.3.0
This will create a new project with the following content in it
│ pom.xml
│
└───src
├───main
│ ├───java
│ │ └───com
│ │ └───entechlog
│ │ └───ksql
│ │ └───functions
│ │ ReverseUdf.java
│ │ SummaryStatsUdaf.java
│ │
│ └───resources
└───test
└───java
└───com
└───entechlog
└───ksql
└───functions
ReverseUdfTests.java
SummaryStatsUdafTests.java
Update pom.xml for required dependencies. The archetype from Confluent includes an example UDF and UDAF, You can use that for testing to make sure your maven setup is correct by issuing the command mvn clean package inside the root project folder
Here I am going to create a custom KSQL function, which will return a capitalized version of the first character of each word in a string. Java code for this function can be found at “https://github.com/entechlog/ksqlDB-udf/blob/master/src/main/java/com/entechlog/ksql/functions/Udf_ToTitleCase.java", Save this as “Udf_ToTitleCase.java” in the same path as “ReverseUdf.java”
Build the project by running the following command in the project root directory
mvn clean package
Now copy the jar(udf-ToTitleCase-0.1.0.jar) to “ksql.extension.dir”
sudo cp udf-ToTitleCase-0.1.0.jar /etc/ksql/ext
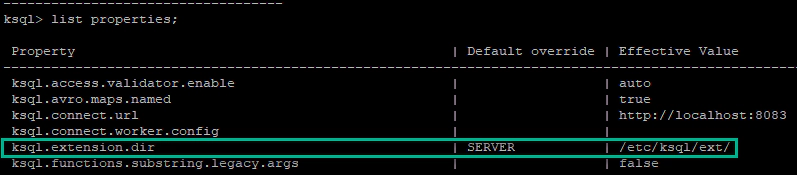
If you don’t have “ksql.extension.dir”, set the same by editing “ksql-server.properties”
nano /etc/ksql/ksql-server.properties
ksql.extension.dir=/etc/ksql/ext/
After the copy (and properties change), restart ksql server based on your installation type
confluent stop ksql-server;
confluent start ksql-server;
confluent status ksql-server;
OR
sudo systemctl stop confluent-ksql.service;
sudo systemctl start confluent-ksql.service;
sudo systemctl status confluent-ksql.service;
Validate the properties and function in a ksql session using below commands
LIST PROPERTIES;
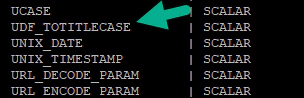
LIST FUNCTIONS;
DESCRIBE FUNCTION UDF_TOTITLECASE;
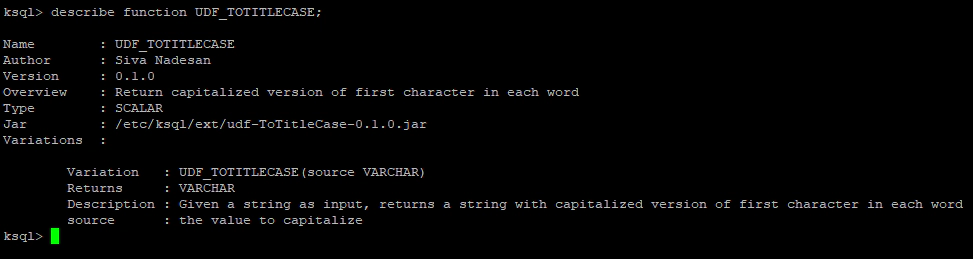
Now to test this, let’s set up some test data using ksql-datagen. If you don’t have “ksql-datagen”, install the same using the below command
sudo confluent-hub install confluentinc/kafka-connect-datagen:latest
Create a schema for your datagen, See “https://github.com/entechlog/ksqlDB-udf/blob/master/datagen/user.avro" for the schema I have created to generate this test data
cd into the directory which has the schema (in this case user.avro) and issue below command. This will generate test data for our topic
ksql-datagen schema=user.avro format=avro topic='dev.etl.datagen.user.src.0020' key=userid maxInterval=5000 iterations=10
Now, Start KSQL session and Issue this command to start reading data from the beginning of the topic
SET 'auto.offset.reset'='earliest';
Check messages in topic using
ksql> PRINT 'dev.etl.datagen.user.src.0020' FROM BEGINNING LIMIT 1;
Format:AVRO
2/22/20 3:24:07 PM EST, 1000, {"userid": "1000", "fullname": "agustin waters", "firstname": "Brice", "lastname": "Dougherty", "countrycode": "AU"}
ksql>
Now lets create a stream on this topic using
CREATE STREAM STM_DATAGEN_USER_SRC_0010 WITH (KAFKA_TOPIC='dev.etl.datagen.user.src.0020', VALUE_FORMAT='Avro');
Validate the function now using below PUSH query. As you see here the function is working as expected
ksql> SELECT userid, fullname, UDF_TOTITLECASE(fullname) FROM STM_DATAGEN_USER_SRC_0010 EMIT CHANGES;
+-------+--------------------------+---------------------+
|USERID |FULLNAME |KSQL_COL_2 |
+-------+--------------------------+---------------------+
|1000 |agustin waters |Agustin Waters |
|1001 |tameka velasquez |Tameka Velasquez |
|1002 |bruno ponce |Bruno Ponce |
Hope this was helpful. I will keep my github page “https://github.com/entechlog/ksqlDB-udf" updated as I explore and create more ksqlDB UDF’s.
Prerequisites Install Confluent platform for your operating system using …

Confluent KSQL is the streaming SQL engine that enables real-time data processing against Apache Kafka®. It provides an …