
Ultimate guide on how to host dbt docs
Overview dbt (data build tool) is a popular open-source tool used for transforming data in your data warehouse. dbt Docs …


Snowpipe is Snowflake’s most cost-efficient method for continuous data ingestion, automatically loading data as files arrive in cloud storage. Unlike traditional batch loading methods or expensive real-time streaming platforms, Snowpipe provides near real-time ingestion (typically 1-3 minutes) with these key advantages:
Near real-time ingestion means files are loaded within minutes of arrival, which is sufficient for most analytical workloads. Event-driven architecture uses cloud notifications (AWS SQS, Google Pub/Sub, Azure Event Grid) to trigger loads automatically. Cost efficiency comes from the serverless model where you only pay for data processed, not idle compute time. High availability is built-in with error handling and retry mechanisms.
If you’ve ever created dozens of Snowpipes manually, copying SQL, changing table names, managing permissions across dev/tst/stg/prd environments, you know the operational toil. Since teams already use dbt to build data models, managing Snowpipes the same way with dbt macros makes perfect sense. The dbt-snowpipe-utils package transforms Snowpipe management from manual processes into a simple, configuration-driven workflow that supports both schema-agnostic VARIANT loading and individual columns with schema inference and evolution.
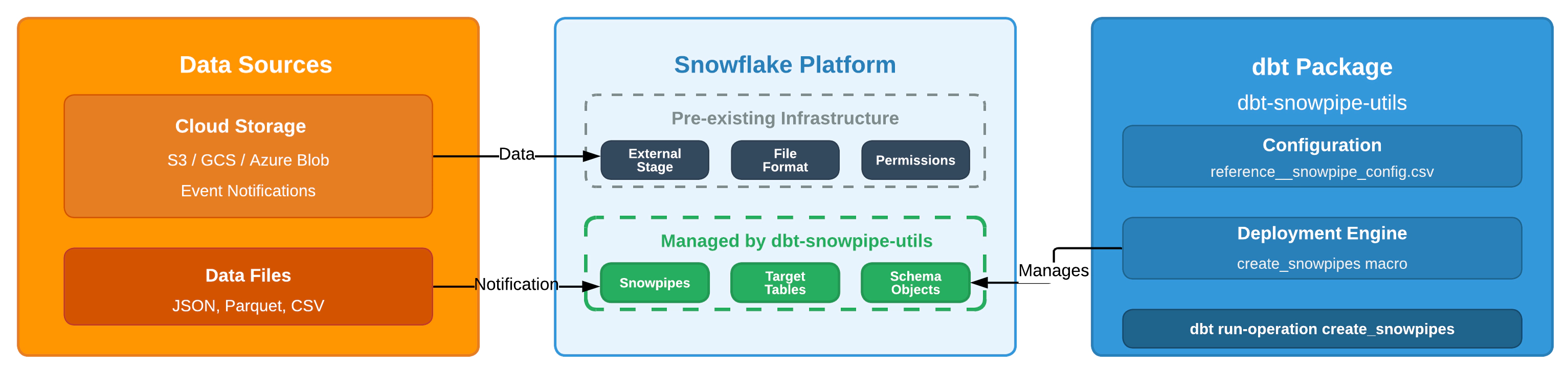
The reality check is important: Snowpipe isn’t real-time streaming, it’s near real-time, but that’s exactly what makes it cost-efficient. You get continuous ingestion without the overhead of always-on streaming infrastructure that costs money even during low-volume periods.
In an ideal world, this would be provisioned with Terraform modules, but when I started, support for Snowflake pipes was limited, so I stuck with this design and haven’t revisited the latest Terraform options.
Scope assumption: Your DATABASE, SCHEMA, INTEGRATION, STAGE, FILE FORMAT, etc., already exist in Snowflake. This blog focuses on using the dbt package to automate Snowpipe, not on provisioning AWS OR Snowflake resources.
Before getting started, ensure you have a Snowflake account with existing objects (DB, SCHEMA, STAGE, FILE FORMAT) ready, dbt (Core or Cloud) with the Snowflake adapter configured, and basic dbt knowledge including models, macros, and project structure.
The package supports three storage approaches, each optimized for different scenarios and data characteristics. Understanding when to use each pattern is crucial for both performance and operational simplicity.
VARIANT mode is the recommended starting point for most teams because it provides immediate value with zero schema management overhead. This approach stores raw JSON in a single DATA VARIANT column for maximum flexibility. It’s ideal when upstream schemas change frequently, you don’t control source systems, or schema evolution is unpredictable. The key insight is that when data is properly partitioned by date, source, or logical boundaries, VARIANT query performance is excellent. Well-partitioned VARIANT tables often outperform poorly partitioned typed tables.
Individual columns mode uses Snowflake’s INFER_SCHEMA() to create typed columns (like user_id, timestamp) automatically for better compression and query performance once schemas stabilize. This approach works best when schemas are relatively stable, downstream consumers prefer typed columns, and storage cost optimization is critical. However, it requires ongoing schema management and becomes more complex when schemas change.
Schema evolution can be enabled with individual columns mode to automatically detect and add new columns as they appear. This is useful for bridging the gap between VARIANT flexibility and typed column performance, especially during gradual migrations from VARIANT to typed columns or when working with systems that have predictable schema additions.
Follow these steps end-to-end to implement the package in your environment. Each step includes verification so you can be confident everything works correctly.
To install the dbt package, add the following to your packages.yml:
packages:
- git: "https://github.com/entechlog/dbt-snowpipe-utils"
revision: main
It’s always better to pin to a tagged release rather than a branch like main for more reproducible and stable builds.
dbt deps
Configure the minimal variables your project needs by editing the following section in your dbt_project.yml. Adjust names to fit your environment:
vars:
dbt_snowpipe_utils:
snowpipe_database: "RAW_DB" # Database where Snowpipes and objects are deployed
snowpipe_schema: "UTIL" # Utility schema for stage, file formats (Snowpipes go in schema from pipe config)
snowpipe_warehouse: "COMPUTE_WH" # Warehouse used by package operations (like initial copy)
snowpipe_admin_role: "SYSADMIN" # Role with privileges to create/alter pipes
snowpipe_monitor_roles: "DBT_ROLE,DATA_ENGINEER" # Comma-separated roles that can monitor
Create or edit seeds/reference__snowpipe_config.csv to define each pipe declaratively. Below is a compact example covering VARIANT mode, typed columns with inference, and optional schema evolution:
stage_name,source_name,event_name,event_type,cluster_key_transformation,cluster_key_type,cluster_key,file_pattern,enable_schema_inference,enable_schema_evolution,dev_enable_pipe_flag,dev_pause_pipe_flag,notes
PARQUET_STAGE,SALES,ORDERS,,event_date,DATE,event_date,parquet,FALSE,FALSE,TRUE,FALSE,VARIANT mode
JSON_STAGE,SALES,CUSTOMERS,,event_date,DATE,event_date,json,TRUE,FALSE,TRUE,FALSE,Individual columns
JSON_STAGE,MARKETING,CAMPAIGNS,,DATE(timestamp),DATE,event_date,json,TRUE,TRUE,TRUE,FALSE,With schema evolution
dbt seed
Query the seeded table in your target schema and confirm that rows exist. The CSV format is used to keep this config fully dbt-native. In the future, this may support YAML-based configs for better structure and readability. The cluster_key currently does not support composite columns. In VARIANT mode, we extract a single column using cluster_key_transformation. In non-VARIANT mode, composite keys are theoretically possible but are not yet supported, this may be enhanced later.
The package intelligently rebuilds only what changed (e.g., toggling pause settings without dropping/recreating pipes). This smart approach means you can safely run deployments without worrying about unnecessary recreation of working pipes.
# Dry run (no changes executed)
dbt run-operation create_snowpipes --args '{"run_queries": false}'
# Dry run, Debug mode
dbt run-operation create_snowpipes --args '{"run_queries": false, "debug_mode": true}'
# Execute (create/update pipes)
dbt run-operation create_snowpipes --args '{"run_queries": true}'
Verify your deployment:
USE DATABASE <database-name>;
USE SCHEMA <schema-name>;
-- validate pipes
SHOW PIPES;
DESC PIPE <pipe-name>;
SELECT SYSTEM$PIPE_STATUS('<database-name>.<schema-name>.<pipe-name>');
-- validate copy history
SELECT *
FROM TABLE(information_schema.copy_history(TABLE_NAME=>'<database-name>.<schema-name>.<table-name>', START_TIME=> DATEADD(hours, -1, CURRENT_TIMESTAMP())));
-- validate data in final table
SELECT * FROM <database-name>.<schema-name>.<table-name>;
This automation package eliminates the manual toil of Snowpipe management while preserving the cost advantages that make Snowpipe attractive. You gain declarative configuration that works like any other dbt code, version control integration for tracking changes, environment consistency across dev/tst/stg/prd deployments, and intelligent updates that rebuild only what has actually changed. Whether you’re landing raw JSON as VARIANT or leveraging typed columns with schema evolution, deployments become declarative, repeatable, and scalable.
Start with VARIANT mode for new data sources, as it provides immediate value with minimal complexity. Ensure your data is partitioned thoughtfully by date, source, or other logical boundaries. Monitor performance using Snowflake’s COPY_HISTORY and pipe monitoring capabilities, and migrate to individual columns only when query patterns and performance requirements justify the additional schema management overhead. Use the enable_pipe_flag and pause_pipe_flag columns to control pipe behavior across different environments without duplicating configuration.
When troubleshooting, first verify that cloud event notifications are configured correctly, confirm that stage and file format definitions match your data structure, and review pipe execution history for any errors. For schema inference failures, ensure sample files exist in your stage, verify that the file format matches your data structure, and check for malformed JSON or data type conflicts.
If you need to back out or decommission pipes, first pause them to prevent new data from loading:
-- Disable pipes first. Pipes can be also diabled from config seed file
alter pipe if exists <pipe_name> set pipe_execution_paused = true;
-- (Optional) Drop pipe
drop pipe if exists UTIL.<pipe_name>;
-- Keep stages/file formats if they're shared.
Remove the package from packages.yml, delete the seed if desired, and run dbt deps again to clean up dependencies.
The dbt-snowpipe-utils package brings ingestion infrastructure into your dbt workflow using infrastructure-as-code principles. Define pipes in a seed file, dry-run to preview changes, and apply when ready. Whether you land raw JSON as VARIANT or promote to typed columns with optional schema evolution, the package keeps deployments declarative, repeatable, and scalable.
This approach combines Snowpipe’s cost-efficient serverless model with dbt’s proven deployment patterns to eliminate manual processes while maintaining operational reliability at scale. Start simple with VARIANT mode, scale to typed columns when justified by performance requirements, and let automation handle the complexity behind the scenes.
Hope this was helpful. Did I miss something? Let me know in the comments.
This blog represents my own viewpoints and not those of my employer. All product names, logos, and brands are the property of their respective owners.
Overview dbt (data build tool) is a popular open-source tool used for transforming data in your data warehouse. dbt Docs …

Unleash the Power of Chatting with Data: A Deep Dive into Snowflake, ChatGPT, dbt, and Streamlit In the era of …