
Integrating Kafka Connect With Amazon Managed Streaming for Apache Kafka (MSK)
In this article, we will see how to integrate Kafka connect with Amazon Managed Streaming for Apache Kafka (MSK). Code …
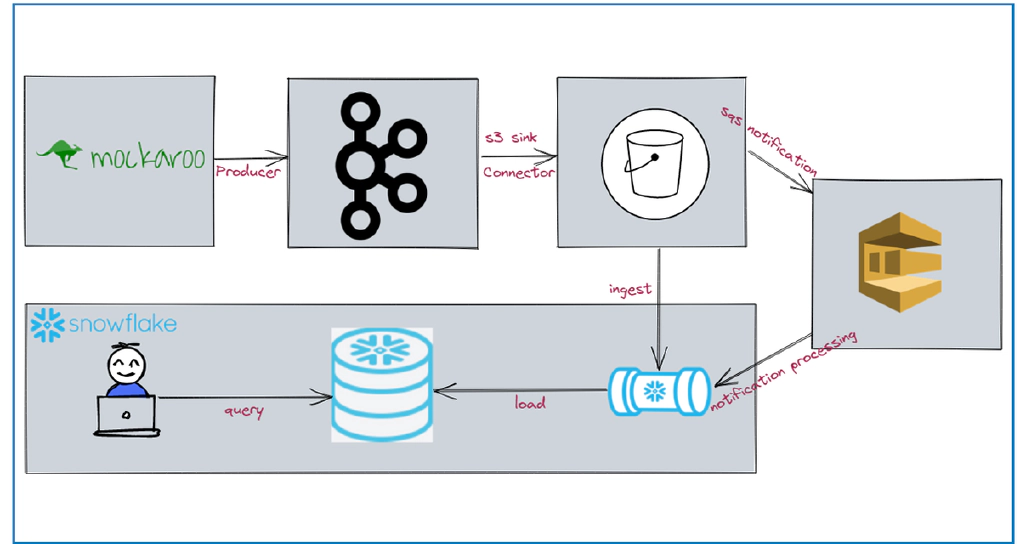

In this article, we will see how to stream data from kafka to snowflake using S3 and Snowpipe. Code used in this article can be found here. Clone the repo to get started. To have stream of data, we will source data from Mockaroo.
Create an s3 bucket which acts as the staging area for incoming events. To automate the bucket creation and IAM provisioning we will use a cloudformation template. You can skip this step, if you already have a s3 bucket and IAM user, role and policy required to read and write data from S3.
Create stack > click Template is ready > click Choose file to upload the cloudformation template s3-bucket-and-iam-user.yaml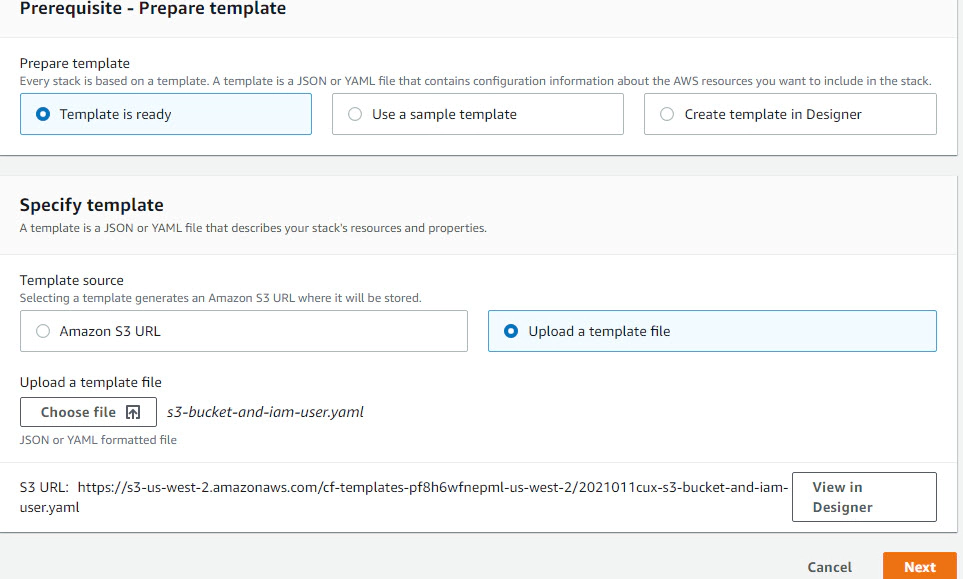
View in Designer to verify the components which will be created. Here we are creating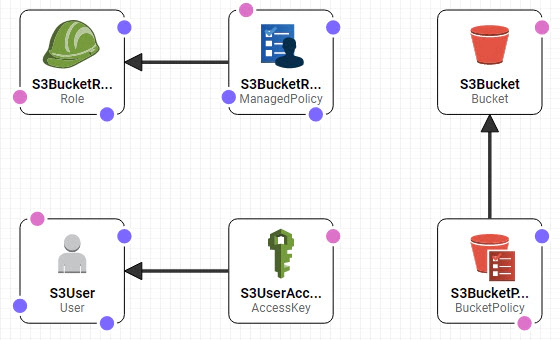
Click next > Give a Stack name (Stack name is bucket name as well) and your IAM User ARN (Temporary, we will change it after we create snowpipe) > click Next > click Next > click Create Stack after reviewing the information.
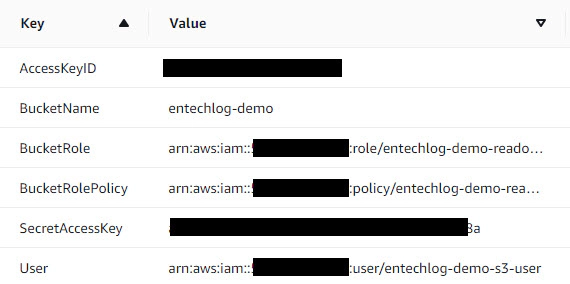
After few minutes you should see CREATE_COMPLETE message. Click output to view the access details for your bucket. Note it down as we would need it for next few steps
The docker-compose.yml will bring up following services
Here is the list of steps which should be done before bringing up the docker services
Create a copy of /kafka-s3-snowpipe/kafka-connect/secrets/connect-secrets.properties.template as /kafka-s3-snowpipe/kafka-connect/secrets/connect-secrets.properties and update with S3 details from the cloudformation output.
Create a copy of .env.template as .env and update it with Mockaroo Key from the Mockaroo schema which you have created.
Update create-s3-sink.sh if you have to change the topic name OR the target s3 bucket directory.
Now we have all required artifacts and the next step to start the Kafka services. Here we will bring up Kafka, produce some data by calling the Mockaroo API in a loop and write the events from kafka topic to s3 bucket using s3 sink connector. All these will happen automatically when we bring up docker-compose.yml
Start the application by running docker-compose up --remove-orphans -d --build in the directory with docker-compose.yml
Validate the status of docker containers by running docker-compose ps
Validate Kafka topics and connector by navigating to control center UI http://your-machine-name:9021/clusters/. We should see data in Kafka topic and S3.
Data in Kafka topic
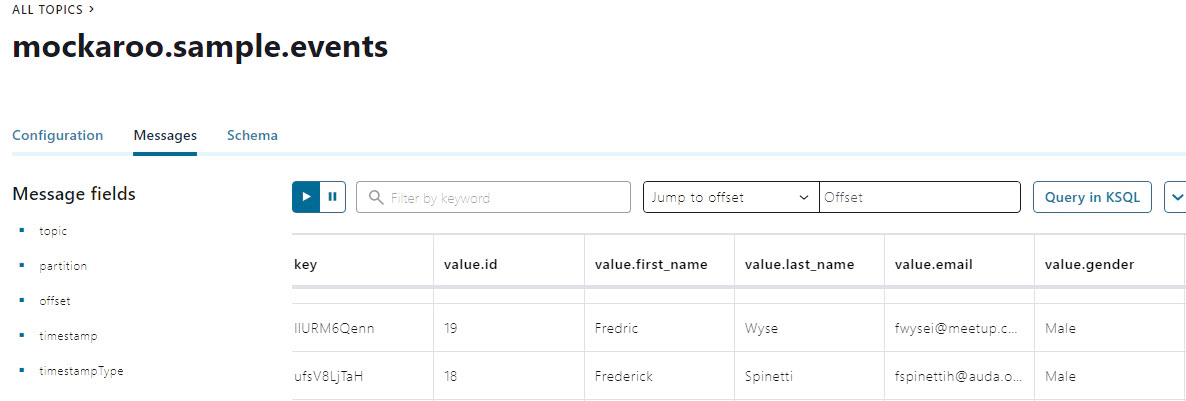
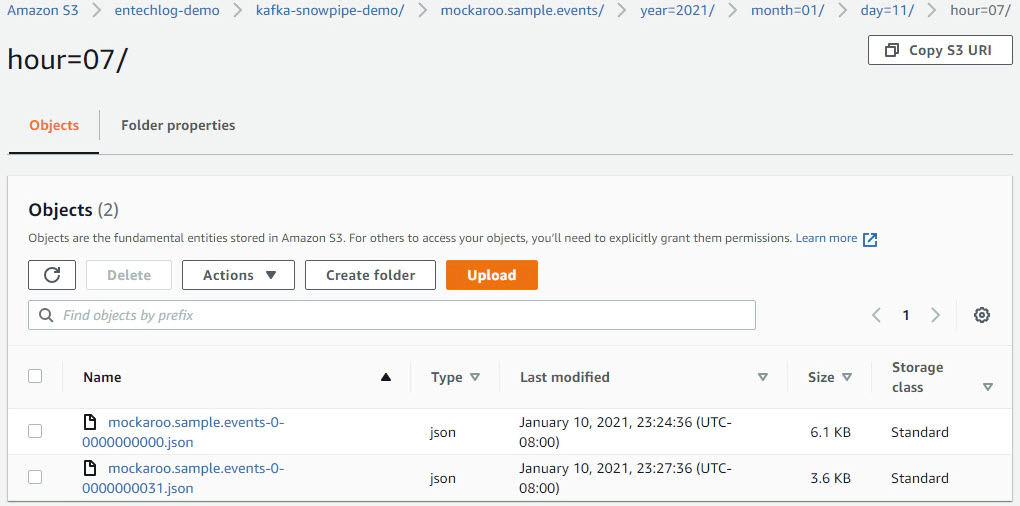
We will create snowpipe and connect with s3 events to enable auto load of data every time we have new events in our s3 staging area. Snowpipe is Snowflake’s continuous data ingestion service. Snowpipe loads data within minutes after files are added to a stage and submitted for ingestion.
Create the demo database
USE ROLE SYSADMIN;
CREATE OR REPLACE DATABASE DEMO_DB;
Create Schema
CREATE OR REPLACE SCHEMA DEMO_DB.SNOWPIPE;
Create storage integration. Update STORAGE_AWS_ROLE_ARN using the output from cloudformation and STORAGE_ALLOWED_LOCATIONS with s3 bucket details
USE ROLE ACCOUNTADMIN;
CREATE OR REPLACE STORAGE INTEGRATION MOCKAROO_S3_INT
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = S3
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = 'iam-role'
STORAGE_ALLOWED_LOCATIONS = ('s3://entechlog-demo/kafka-snowpipe-demo/');
Describe Integration and retrieve the AWS IAM User (STORAGE_AWS_IAM_USER_ARN and STORAGE_AWS_EXTERNAL_ID) for Snowflake Account
DESC INTEGRATION MOCKAROO_S3_INT;
Grant the IAM user permissions to access S3 Bucket. Navigate to IAM in AWS console, click Roles > click your role name from cloudformation output > click Trust relationships > click Edit trust relationship > Update the Principal with STORAGE_AWS_IAM_USER_ARN and sts:ExternalId with STORAGE_AWS_EXTERNAL_ID > click Update Trust Policy. Now we have replaced the temporary details which we gave when creating the role in cloudformation with the correct snowflake account and external ID.
Create file format for incoming files
CREATE OR REPLACE FILE FORMAT DEMO_DB.SNOWPIPE.MOCKAROO_FILE_FORMAT
TYPE = JSON COMPRESSION = AUTO TRIM_SPACE = TRUE NULL_IF = ('NULL', 'NULL');
Create stage for incoming files. Update URL with s3 bucket details
CREATE OR REPLACE STAGE DEMO_DB.SNOWPIPE.MOCKAROO_S3_STG
STORAGE_INTEGRATION = MOCKAROO_S3_INT
URL = 's3://entechlog-demo/kafka-snowpipe-demo/'
FILE_FORMAT = MOCKAROO_FILE_FORMAT;
Create target table for JSON data
CREATE OR REPLACE TABLE DEMO_DB.SNOWPIPE.MOCKAROO_RAW_TBL (
"event" VARIANT
);
Create snowpipe to ingest data from STAGE to TABLE
CREATE
OR REPLACE PIPE DEMO_DB.SNOWPIPE.MOCKAROO_SNOWPIPE AUTO_INGEST = TRUE AS COPY
INTO DEMO_DB.SNOWPIPE.MOCKAROO_RAW_TBL
FROM @DEMO_DB.SNOWPIPE.MOCKAROO_S3_STG;
Describe snowpipe and copy the ARN for notification_channel
SHOW PIPES LIKE '%MOCKAROO_SNOWPIPE%';
Now is the time to connect S3 and snowpipe. Navigate to Amazon S3 > click your bucket > click Properties > click Create event notification > Update Event name, Prefix and Suffix > Set Event types as All object create events > Update Destination as SQS queue and click Enter SQS queue ARN from the snowpipe
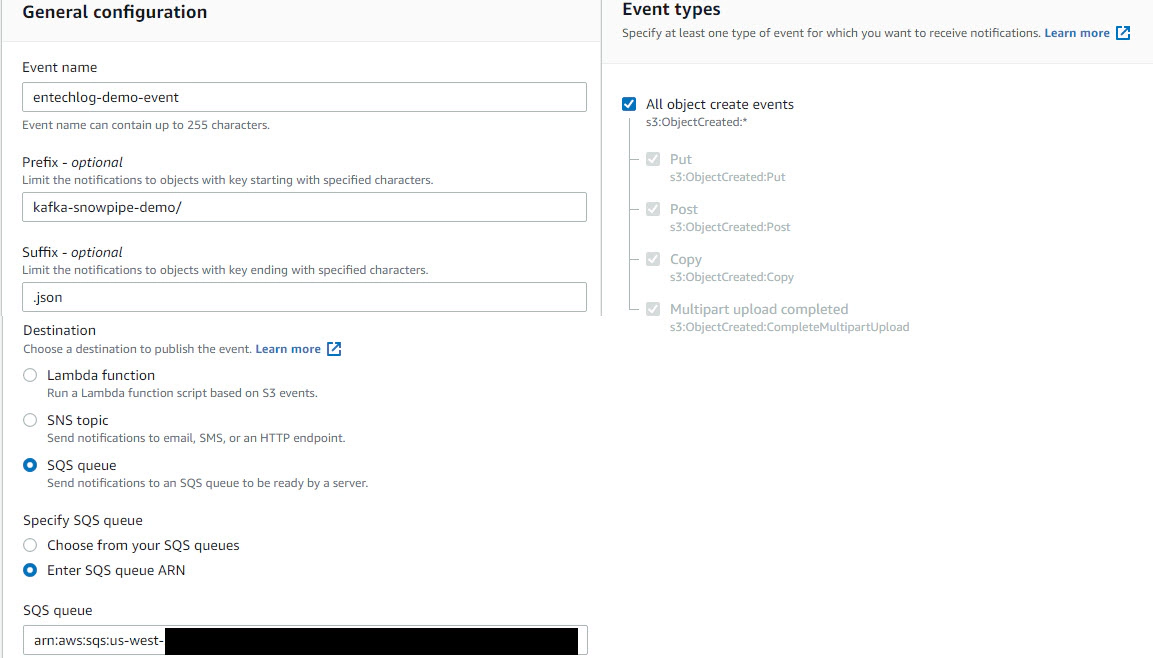
Validate the snowpipe status
SELECT SYSTEM$PIPE_STATUS('DEMO_DB.SNOWPIPE.MOCKAROO_SNOWPIPE');
Validate data in snowflake
SELECT * FROM DEMO_DB.SNOWPIPE.MOCKAROO_RAW_TBL;
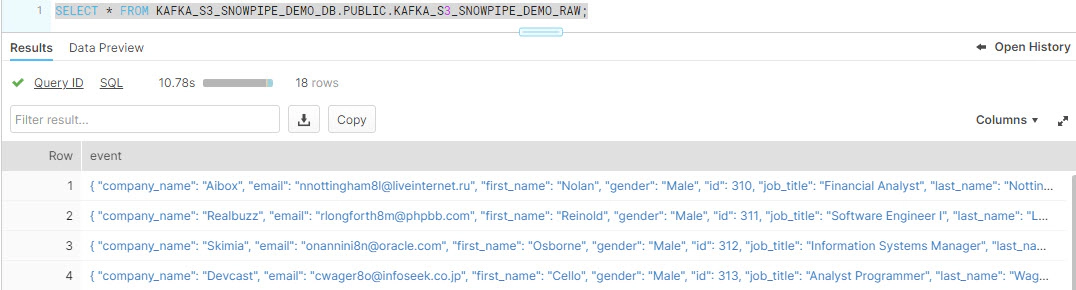
This data in RAW tables can be further processed by streams and tasks enabling end to end stream processing.
We could also create a parsed table and load it directly from a snowpipe.
-- Create parsed table
CREATE OR REPLACE TABLE DEMO_DB.SNOWPIPE.MOCKAROO_PARSED_TBL (
"log_ts" TIMESTAMP,
"path_name" STRING,
"file_name" STRING,
"file_row_number" STRING,
"id" STRING,
"first_name" STRING,
"last_name" STRING,
"gender" STRING,
"company_name" STRING,
"job_title" STRING,
"slogan" STRING,
"email" STRING
);
-- Create snowpipe to load parsed table
CREATE PIPE DEMO_DB.SNOWPIPE.MOCKAROO_PARSED_SNOWPIPE AUTO_INGEST = TRUE AS COPY
INTO DEMO_DB.SNOWPIPE.MOCKAROO_PARSED_TBL
FROM (
SELECT current_timestamp::TIMESTAMP log_ts
,left(metadata$filename, 77) path_name
,regexp_replace(metadata$filename, '.*\/(.*)', '\\1') file_name
,metadata$file_row_number file_row_number
,$1:id
,$1:first_name
,$1:last_name
,$1:gender
,$1:company_name
,$1:job_title
,$1:slogan
,$1:email
FROM @DEMO_DB.SNOWPIPE.MOCKAROO_S3_STG
);
-- Validate data in parsed table
SELECT * FROM DEMO_DB.SNOWPIPE.MOCKAROO_PARSED_TBL;

Hope this was helpful. Did I miss something ? Let me know in the comments and I’ll add it in !
docker container ls -adocker-compose downdocker-compose down --volumesdocker rm $(docker ps -q -f status=exited)
In this article, we will see how to integrate Kafka connect with Amazon Managed Streaming for Apache Kafka (MSK). Code …

In this article, we will see how to use the Snowflake connector to stream data from Kafka to Snowflake. The Snowflake …