
Automating Snowpipe Deployment with dbt
Overview Snowpipe is Snowflake’s most cost-efficient method for continuous data ingestion, automatically loading …
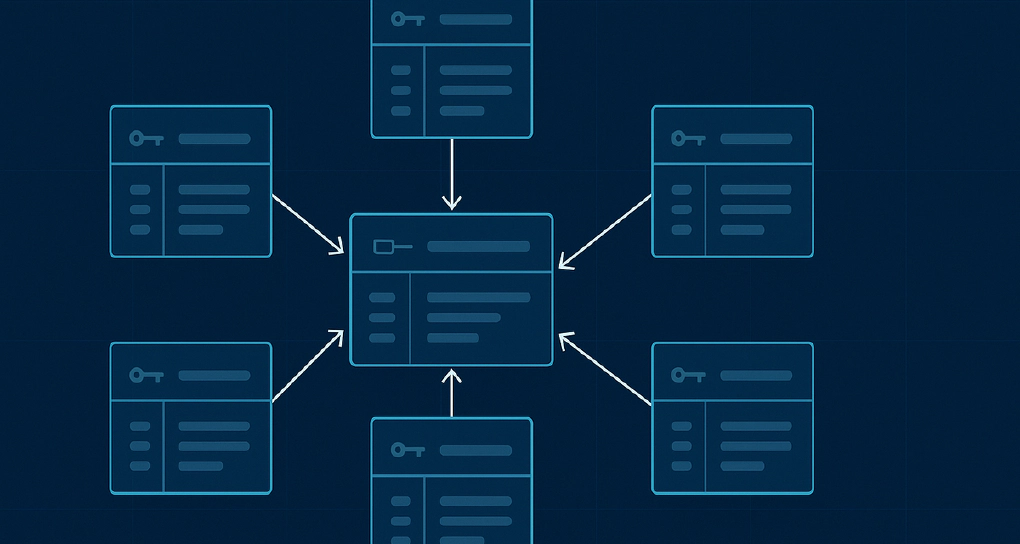

Not enough teams focus on conceptual modeling of data before creating dbt models. Even fewer maintain documentation of their data models, and when they do, it’s usually a manual ER diagram that becomes stale the moment it’s created. You know the story: someone creates a beautiful ERD in Lucidchart or draw.io during the initial project phase, but three sprints later, it’s completely out of sync with the actual dbt models in production.
The problem isn’t that data teams don’t care about documentation. The problem is manual maintenance doesn’t scale. When you’re shipping new models every week, updating diagrams manually is the first thing that gets deprioritized. The result? New team members struggle to understand table relationships, analysts waste time reverse-engineering joins, and stakeholders can’t visualize how data flows through your warehouse.
Enter dbt-model-erd, a Python package that automatically generates beautiful, interactive entity-relationship diagrams directly from your dbt models. It intelligently detects relationships between fact and dimension tables, infers primary and foreign keys, and embeds diagrams right into your dbt documentation. No manual updates. No stale diagrams. Just fresh, accurate ERDs that stay in sync with your code.

If you’re already using dbt to build data models, adding automated ERD generation is a natural next step. Your dbt models already contain relationship metadata through ref() functions and join conditions in your SQL. dbt-model-erd extracts this information and transforms it into visual diagrams using Mermaid.js, which renders beautifully in modern browsers and integrates seamlessly with dbt docs.
Scope assumption: This blog focuses on using dbt-model-erd to automate ERD generation for existing dbt projects. We assume you already have a working dbt project with models and relationships defined through ref() functions.
Before getting started, ensure you have a working dbt project with models and relationships defined, Python 3.8 or higher installed, and basic understanding of dbt concepts like models and the ref() function.
dbt-model-erd is a lightweight Python package that generates ERDs automatically by analyzing your dbt project structure. It works by:
ref() functions and SQL join conditions_pk, _fk, _key)The package understands dimensional modeling patterns commonly used in analytics engineering. It recognizes star schemas, snowflake schemas, and bridge tables, automatically laying out diagrams in a way that makes sense for analytics workloads.
Key features include:
Unlike tools that require extensive configuration or external database connections, dbt-model-erd works entirely from your dbt project files. This means it’s fast, doesn’t require database credentials, and can run in any environment where Python exists.
Install dbt-model-erd via pip:
pip install dbt-model-erd
For production environments, pin to a specific version in your requirements.txt: dbt-model-erd==0.1.0
Confirm the package is installed correctly:
python -m dbt_erd --help
Navigate to your dbt project root and generate your first diagram:
# Generate ERD for all fact models
python -m dbt_erd --model-path models/fact
# Generate ERD for a specific model
python -m dbt_erd --model-path models/fact/fact_orders.sql
Create a configuration file erd_config.yml in your dbt project root:
theme: default
direction: LR # Left-to-right layout
show_all_columns: true
max_columns: 10
Run with configuration:
python -m dbt_erd --model-path models/fact --config erd_config.yml
The best way to understand dbt-model-erd is to see it in action. The dbt-examples/dbt-erd repository demonstrates a complete e-commerce dimensional model with automatic ERD generation.
The dbt-erd example follows dimensional modeling best practices with a layered architecture:
models/
├── prep/ # Preparation layer (staging)
│ ├── prep_customers.sql
│ ├── prep_products.sql
│ └── prep_orders.sql
└── dw/ # Data warehouse layer
├── dimensions/
│ ├── dim_customer.sql
│ ├── dim_product.sql
│ └── dim_date.sql
└── facts/
├── fact_orders.sql
└── fact_sales.sql
Dimension tables provide context and descriptive attributes:
-- dim_customer.sql
{{ config(materialized='table') }}
select
{{ dbt_utils.generate_surrogate_key(['customer_id']) }} as customer_key,
customer_id,
customer_name,
email,
city,
country,
created_at
from {{ ref('prep_customers') }}
Fact tables store measurable business events:
-- fact_orders.sql
{{ config(materialized='table') }}
select
{{ dbt_utils.generate_surrogate_key(['order_id']) }} as order_key,
order_id,
{{ dbt_utils.generate_surrogate_key(['customer_id']) }} as customer_key,
{{ dbt_utils.generate_surrogate_key(['product_id']) }} as product_key,
order_date,
quantity,
amount
from {{ ref('prep_orders') }}
dbt-model-erd detects relationships automatically by analyzing the ref() functions in your SQL and identifying foreign key patterns in column names:
# schema.yml
models:
- name: fact_orders
description: Orders fact table
columns:
- name: order_key
description: Primary key for orders
- name: customer_key
description: Foreign key to dim_customer
- name: product_key
description: Foreign key to dim_product
The tool identifies that customer_key and product_key are foreign keys based on the _key suffix pattern and traces relationships through the ref() functions in the SQL model.
Clone the example repository and run:
git clone https://github.com/entechlog/dbt-examples.git
cd dbt-examples/dbt-erd
# Using Docker (recommended)
docker-compose up
# Or locally with Python
dbt deps
dbt build
python -m dbt_erd --model-path models/dw/facts
The tool generates interactive HTML files with Mermaid diagrams showing fact tables, dimension tables, relationships, and column details. The generated HTML files are saved to assets/img/models/dw/fact/fact_orders_model.html (path configurable).
Reference the generated HTML diagram in your model documentation:
# schema.yml
models:
- name: fact_orders
description: |
## Orders Fact Table
This table stores one row per order line item.
### Entity Relationship Diagram
[View interactive diagram](/assets/img/dw/fact/fact_orders_model.html)
Run dbt docs generate && dbt docs serve to see the interactive ERD in your documentation site.
The example repository includes a complete Docker setup for quick experimentation:
# One command to build, test, and generate ERD
docker-compose up
This demonstrates how automated ERD generation fits naturally into your development workflow.
Create detailed configuration files to control diagram output. For a comprehensive list of all available options, see the advanced_config.yml example.
# erd_config.yml
visualization:
max_dimensions: 10 # Maximum number of dimensions to include
show_columns: true # Display table columns
column_limit: 15 # Maximum columns to display per table
mermaid:
theme: forest # Options: default, forest, dark, neutral
direction: LR # LR (left-right) or TB (top-bottom)
outputs:
mmd: false # Generate raw Mermaid source
html: true # Generate interactive HTML
Use configuration in your command:
python -m dbt_erd --model-path models/dw --config erd_config.yml
Generate ERDs for specific model patterns:
# Only fact tables
python -m dbt_erd --model-path models/dw/facts
# Specific fact model
python -m dbt_erd --model-path models/dw/facts/fact_orders.sql
# With custom configuration
python -m dbt_erd --model-path models/dw/facts --config erd_config.yml
Automated ERD generation provides significant value across data organizations:
Faster Onboarding: New team members understand table relationships visually without lengthy explanations or outdated documentation. Auto-generated ERDs in dbt docs serve as the single source of truth.
Improved Collaboration: Visual diagrams create a shared language across engineering, analytics, and business teams. Stakeholders understand data model structure without needing to read SQL.
Reduced Maintenance Overhead: Documentation updates happen automatically as part of the build process. No separate documentation sprints or manual diagram tools required.
Better Code Reviews: ERDs in pull requests help reviewers understand architectural changes before diving into SQL. Unintended relationship impacts become visible immediately.
Self-Service Analytics: Analysts reference ERDs to understand join paths and relationship cardinalities, reducing interruptions to engineering teams and enabling independent query development.
Quality Assurance: ERDs provide quick visual reference to understand table relationships, helping identify missing joins or incorrect relationship patterns during development.
Architectural Governance: Platform teams enforce dimensional modeling standards by reviewing ERDs during code reviews, ensuring consistent use of star schemas and surrogate keys.
Start small by generating ERDs for just your core fact tables and key dimensions. As teams see value, expand to comprehensive project-wide ERD generation.
Data modeling documentation shouldn’t be a manual chore that falls behind the moment you create it. By automating ERD generation directly from your dbt models, you eliminate maintenance overhead while ensuring diagrams stay perfectly in sync with production code.
dbt-model-erd makes this automation trivial. Install the package, point it at your models directory, and get interactive HTML diagrams embedded in dbt docs. No external dependencies, no complex configuration, no manual updates. Just fresh, accurate ERDs that reflect your current data warehouse state.
The broader lesson is this: automate everything that can be derived from code. Your dbt models already contain relationship metadata through ref() functions and SQL joins. Extracting that information into visual diagrams shouldn’t require extra work—it should happen automatically as part of your build process.
Try dbt-model-erd:
pip install dbt-model-erdContribute:
Special thanks to the teams behind dbt-diagrams and dbterd for pioneering automated ERD generation in the dbt ecosystem. Their work inspired this project and demonstrated the value of treating diagrams as code. The dbt community benefits when we build on each other’s ideas and share solutions to common problems.
Hope this was helpful. Did I miss something? Let me know in the comments.
This blog represents my own viewpoints and not those of my employer. All product names, logos, and brands are the property of their respective owners.
Overview Snowpipe is Snowflake’s most cost-efficient method for continuous data ingestion, automatically loading …

Overview dbt (data build tool) is a popular open-source tool used for transforming data in your data warehouse. dbt Docs …