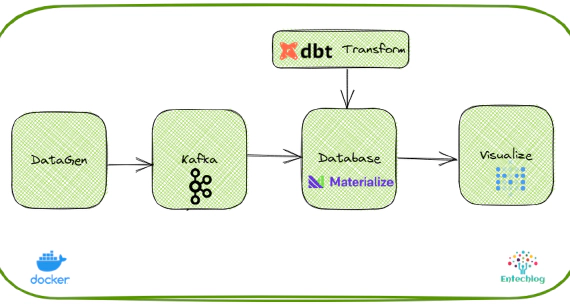
How to setup dbt for Materialize database with streaming data from Kafka
Materialize is a streaming database for real-time applications. Materialize accepts input data from a variety of …

Materialize is a streaming database for real-time applications. Materialize accepts input data from a variety of streaming sources (like Kafka, redpanda), data stores and databases (like S3 and Postgres), and files (like CSV and JSON), and lets you query them using SQL. In this article, we will see how to initialize and configure a new dbt project for Materialize database.
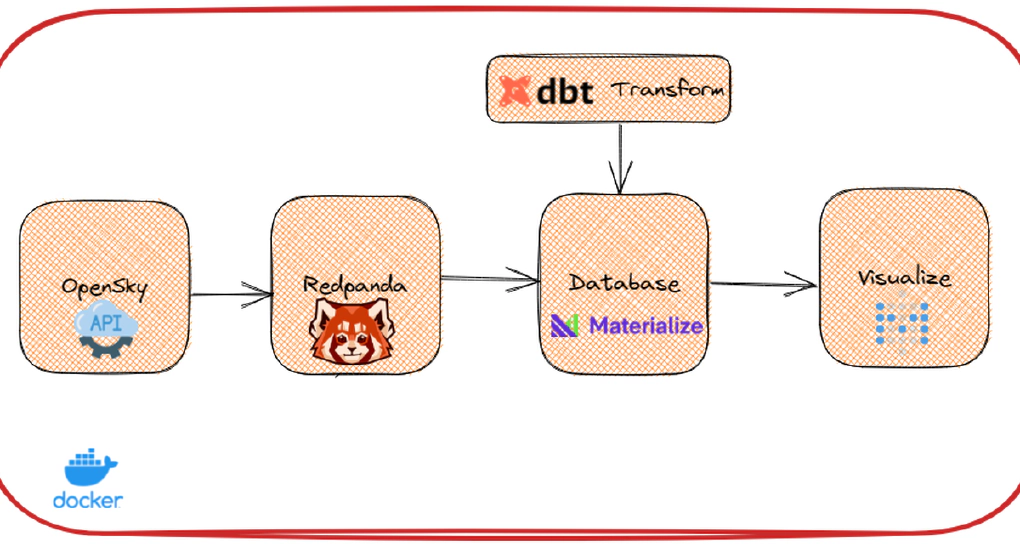
Code used in this article can be found here. We will use OpenSky Network API and Redpanda to generate stream of data, dbt to create source, materialized views in Materialize database and Metabase to create dashboards.
Download and install docker for your platform. Click here for instructions
Create the infrastructure (Redpanda, Materialize, dbt, Metabase) required for this demo using Docker containers.
Open a new terminal and cd into dbt-docker directory. This directory contains infra components for this demo
cd dbt-docker
Create a copy of .env.template as .env. This contains all environment variables for docker, but we don’t have any variables which should be changed for the purpose of this demo
Start dbt container by running
docker-compose up -d --build
Start Materialize container by running
docker-compose -f docker-compose-materialize-redpanda.yml up -d --build
Now we should have all the infrastructure components required for this demo up and running as docker containers.
Validate the containers by running
docker ps
SSH into the materialize cli container by running
docker exec -it mzcli /bin/bash
Connect to materialize DB from cli container and validate materialize by running
psql -U materialize -h materialized -p 6875 materialize
show objects;
If you change the credentials in .env then please make sure to use them
SSH into the dbt container by running
docker exec -it dbt /bin/bash
Validate dbt and materialize plugin is installed correctly by running
dbt --version
SSH into the Redpanda container by running
docker exec -it redpanda /bin/bash
Check topic list created by running
rpk topic list
Check data in topic from data generator by running
rpk topic consume flight_information
To exit the consumer, press Ctrl+C
Next few steps should be exected from the dbt container
cd into your preferred directory
cd /C/
Create dbt project by running
dbt init dbt-materialize-redpanda
Navigate into dbt-materialize-redpanda directory from your code editor like vscode and create a new dbt profile file profiles.yml and update it with Materialize database connection details
dbt-materialize-redpanda:
target: dev
outputs:
dev:
type: materialize
threads: 1
host: materialized
port: 6875
user: materialize
pass: password
dbname: materialize
schema: public
Edit the dbt_project.yml to connect to the profile which we just created. The value for profile should exactly match with the name in profiles.yml
From the dbt container and project directory, run dbt-set-profile to update DBT_PROFILES_DIR. This helps to easily switch between multiple dbt projects
dbt-set-profile is alias to unset DBT_PROFILES_DIR && export DBT_PROFILES_DIR=$PWD
Update name in dbt_project.yml to appropriate project name (say dbt_materialize_redpanda_demo)
Validate the dbt profile and connection by running
dbt debug
Delete the contents from data, macros, models, tests and snapshots directories to follow along this demo
Lets also add dbt variables for redpanda endpoint. To define variables in a dbt project, add a vars config to dbt_project.yml file
vars:
redpanda_broker: 'redpanda:9092'
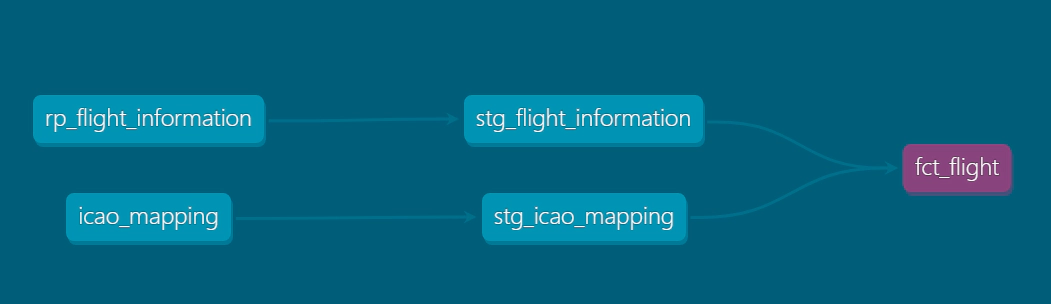
Source represent a connection to the data you want Materialize to process, as well as details about the structure of that data. Materialize source is not same as dbt sources
We will use a redpanda topic as source for this demo. Materialize sources are defined using sql
Copy the source sql from dbt-materialize-redpanda\demo-artifacts\models\source to dbt-materialize-redpanda\models\source. Here is an example of source configuration
{{ config(
materialized='source',
tags = ["source","redpanda"])
}}
{% set source_name %}
{{ mz_generate_name('rp_flight_information') }}
{% endset %}
CREATE SOURCE {{ source_name }}
FROM KAFKA BROKER {{ "'" ~ var('redpanda_broker') ~ "'" }} TOPIC 'flight_information'
KEY FORMAT BYTES
VALUE FORMAT BYTES
ENVELOPE UPSERT;
Review or update the schema and default dbt materialized configuration for source in dbt_project.yml. Here we are specifying all source data to be written into a schema named source in materialized DB.
models:
dbt_materialize_redpanda_demo:
# Config indicated by + and applies to all files under models/sources/
materialized: view
sources:
+materialized: sources
+schema: sources
Create the source by running below command
dbt run --model tag:source --target dev
Sources will created with public_ prefix instead of the schema name which was specified in the configuration. To change this, we will override the dbt macro generate_schema_name which is responsible to generate schema names.
Macros are pieces of code that can be reused multiple times.
Copy the macros from dbt-materialize-redpanda\demo-artifacts\macros\utils to dbt-materialize-redpanda\macros\utils
Macro generate_schema_name uses the custom schema when provided. In this case macro helps to create schema name without the prefix.
Recreate sources by running below command
dbt run --model tag:source --target dev
Now source will be created in correct schema without the public_ prefix
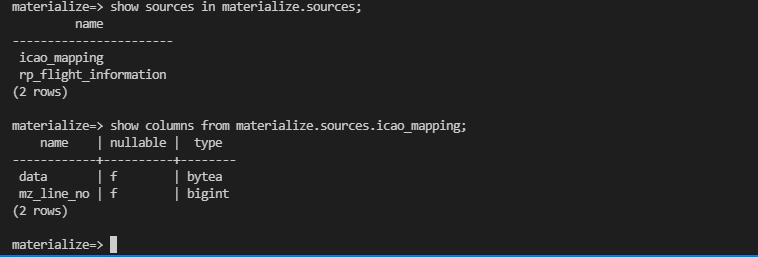
Validate the sources by running below command from the Materialize DB CLI container
show sources in materialize.sources;
show columns from materialize.sources.rp_flight_information;
show columns from materialize.sources.icao_mapping;
Model is a select statement. Models are defined in .sql file. Materialize supports following dbt materializations for models.
✅ source
✅ view
✅ materializedview
✅ index
✅ sink
✅ ephemeral
Create view from the source. Non-materialized view doesn’t store the results of the query but simply provides an alias for the embedded SELECT statement
Copy the model definition from dbt-materialize-redpanda\demo-artifacts\models\staging\ to dbt-materialize-redpanda\models\staging\. Here is an example of view configuration
{{ config(materialized = 'view', alias = 'stg_flight_information', tags = ["staging"]) }}
WITH source AS (
SELECT * FROM {{ ref('rp_flight_information') }}
),
converted AS (
SELECT convert_from(data, 'utf8') AS data FROM source
),
casted AS (
SELECT cast(data AS jsonb) AS data FROM converted
),
renamed AS (
SELECT
(data->>'icao24')::string as icao24,
(data->>'callsign')::string as callsign,
(data->>'origin_country')::string as origin_country,
(data->>'time_position')::numeric as time_position,
(data->>'last_contact')::numeric as last_contact,
(data->>'longitude')::double as longitude,
(data->>'latitude')::double as latitude,
(data->>'baro_altitude')::double as baro_altitude,
(data->>'on_ground')::boolean as on_ground,
(data->>'velocity')::double as velocity,
(data->>'true_track')::double as true_track,
(data->>'vertical_rate')::string as vertical_rate,
(data->>'sensors')::string as sensors,
(data->>'geo_altitude')::string as geo_altitude,
(data->>'squawk')::string as squawk,
(data->>'spi')::string as spi,
(data->>'position_source')::string as position_source
FROM casted
)
SELECT * FROM renamed
Review the model configuration in dbt_project.yml. The model configuration should have project name followed by names which should match with the structure of models directory
models:
dbt_materialize_redpanda_demo:
# Config indicated by + and applies to all files under models/sources/
materialized: view
sources:
+materialized: sources
+schema: sources
staging:
+schema: staging
+materialized: view
marts:
+schema: marts
+materialized: materializedview
Default materialized configuration can be specified at model project level. materialized configuration can be overridden at each directory level
Create views by running below command
dbt run --model tag:staging --target dev
Create materialized view from regular view. Materialized view store the results of the query continuously as the underlying data changes
Copy the model definition from dbt-materialize-redpanda\demo-artifacts\models\materialize\ to dbt-materialize-redpanda\models\materialize\. Here is an example of materialized view configuration
{{ config(materialized = 'materializedview', alias = 'fct_flight', tags = ["marts"]) }}
SELECT fi.icao24,
manufacturername,
model,
operator,
origin_country,
time_position,
longitude,
latitude
FROM {{ ref('stg_flight_information') }} fi
JOIN {{ ref('stg_icao_mapping') }} icao ON fi.icao24 = icao.icao24
Build models by running below command
dbt run --model tag:marts --target dev
dbt packages are in fact standalone dbt projects, with models and macros that tackle a specific problem area.
Create a new file named in packages.yml inside dbt-materialize directory and add package configuration
Specify the package(s) you wish to add
packages:
- package: dbt-labs/codegen
version: 0.5.0
Install the packages by running
dbt deps
Tests are assertions you make about your models and other resources in your dbt project (e.g. sources, seeds and snapshots).
Types of tests:
schema tests (more common)
data tests: specific queries that return 0 records
Generate the yaml for existing models by running
dbt run-operation generate_model_yaml --args '{"model_name": "fct_flight"}'
schema tests can be added at table level OR column level. Here is an example of test under column definition in model yaml
version: 2
models:
- name: fct_flight
description: ""
columns:
- name: icao24
description: "Unique ICAO 24-bit address of the transponder in hex string representation."
tests:
- not_null
Execute tests by running below command
dbt test --models +tag:marts
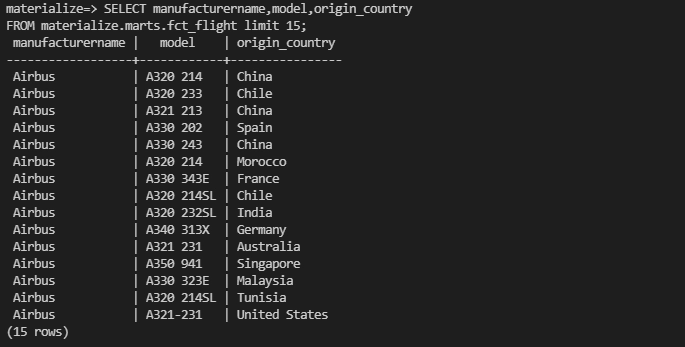
Validate data by running below sql in materialize cli
SELECT manufacturername,model,origin_country
FROM materialize.marts.fct_flight limit 15;
Press Q to exit the query window
dbt docs provides a way to generate documentation for your dbt project and render it as a website.
You can add descriptions to models, columns, sources in the related yml file
dbt also supports docs block using the jinja docs tag
Copy sample jinja docs from dbt-materialize-redpanda\demo-artifacts\docs\ to dbt-materialize-redpanda\docs\
Generate documents by running
dbt docs generate
Publish the docs by running
dbt docs serve --port 8085
Stop published docs by running ctrl + c
Navigate to Metabase UI
Follow the instructions to finish the initial setup of Metabase
Use the following parameters to connect Metabase to your Materialize instance
| Property | Value |
|---|---|
| Database type | PostgreSQL |
| Name | demo |
| Host | materialized |
| Port | 6875 |
| Database name | materialize |
| Database username | materialize |
| Database password | Leave empty |
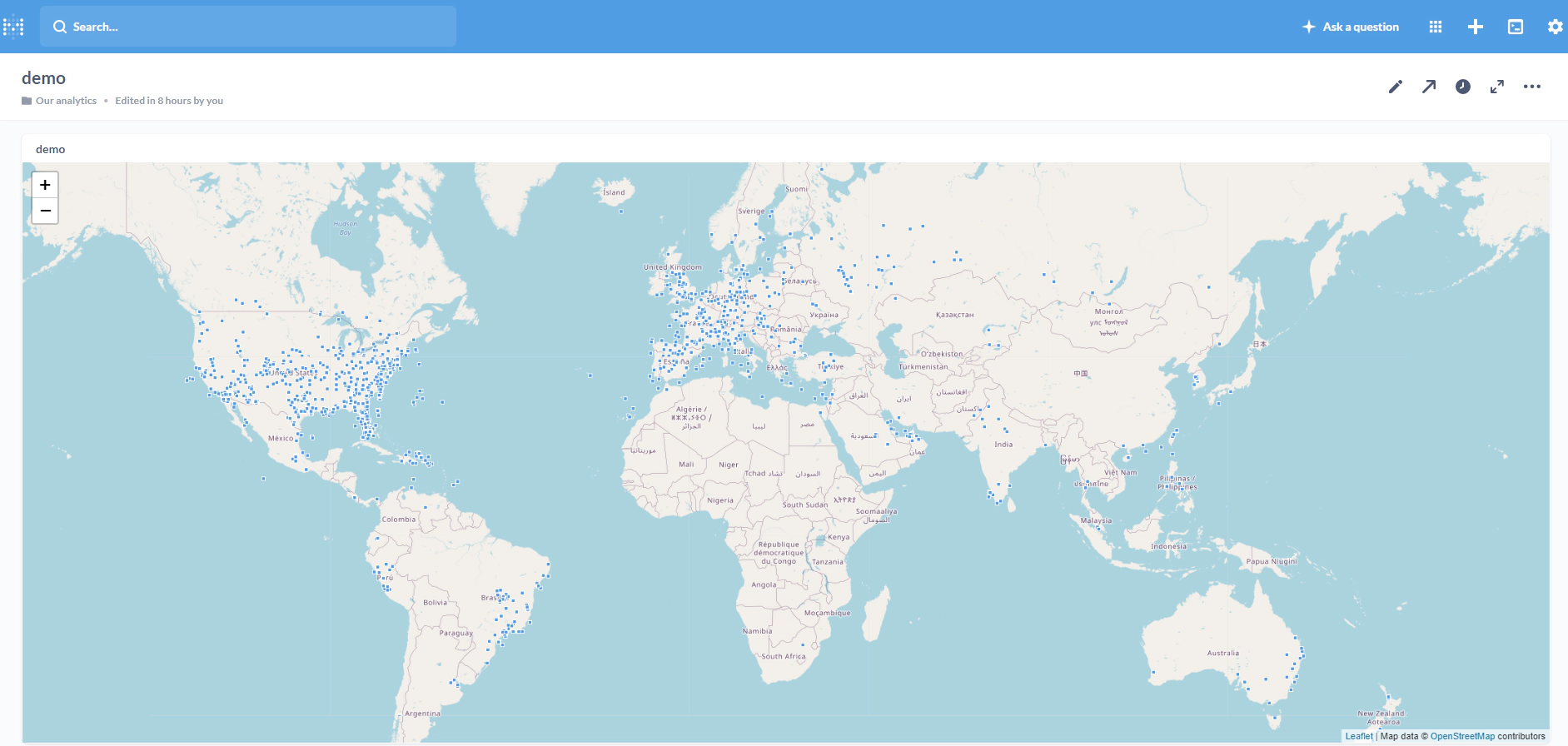
Now we should be able to browse the tables and create dashboards as the one shown below powered by real-time data from Materialize DB.
Open a new terminal and cd into dbt-docker directory. Run the below command to delete the docker containers and related volumes
docker-compose -f docker-compose-materialize-redpanda.yml down -v
docker-compose down -v --remove-orphans
Hope this was helpful. Did I miss something ? Let me know in the comments.
Materialize is a streaming database for real-time applications. Materialize accepts input data from a variety of …

In this article, we will see how to initialize and configure a new dbt project for postgres database. Code used in this …